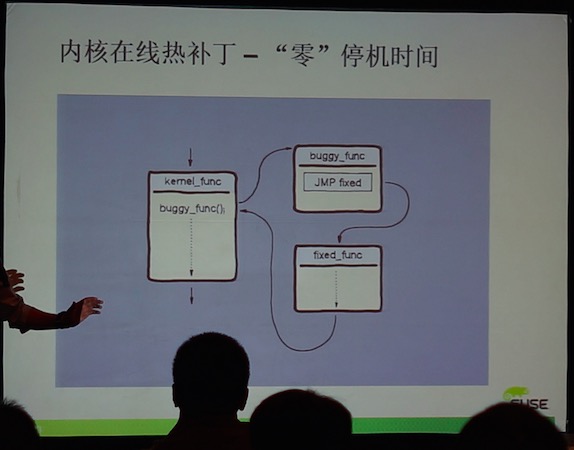
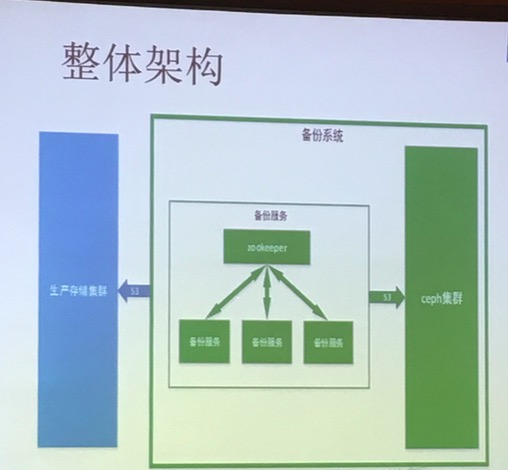
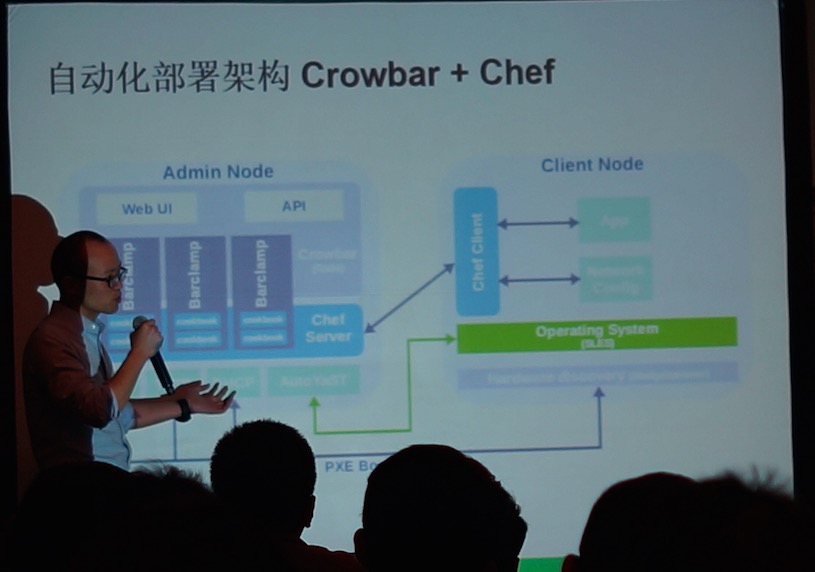
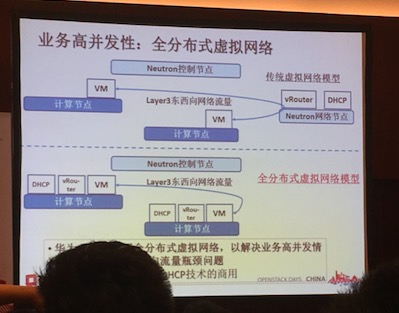
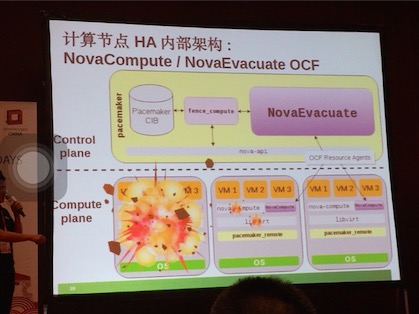
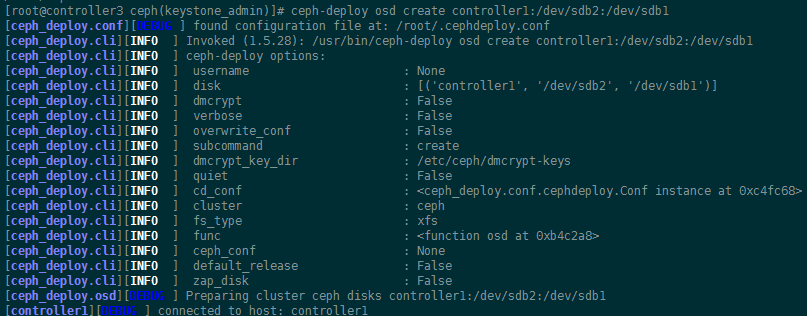
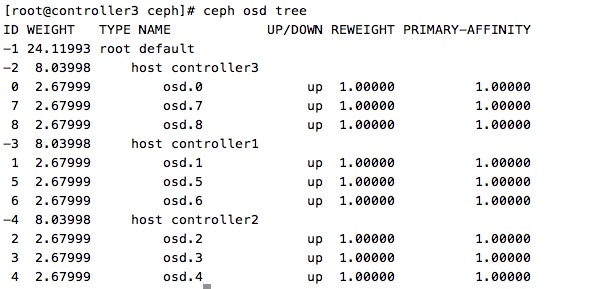
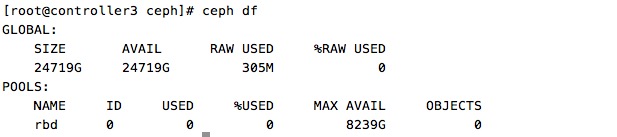
环境:CentOS 7 OpenStack Liberty
拓扑:
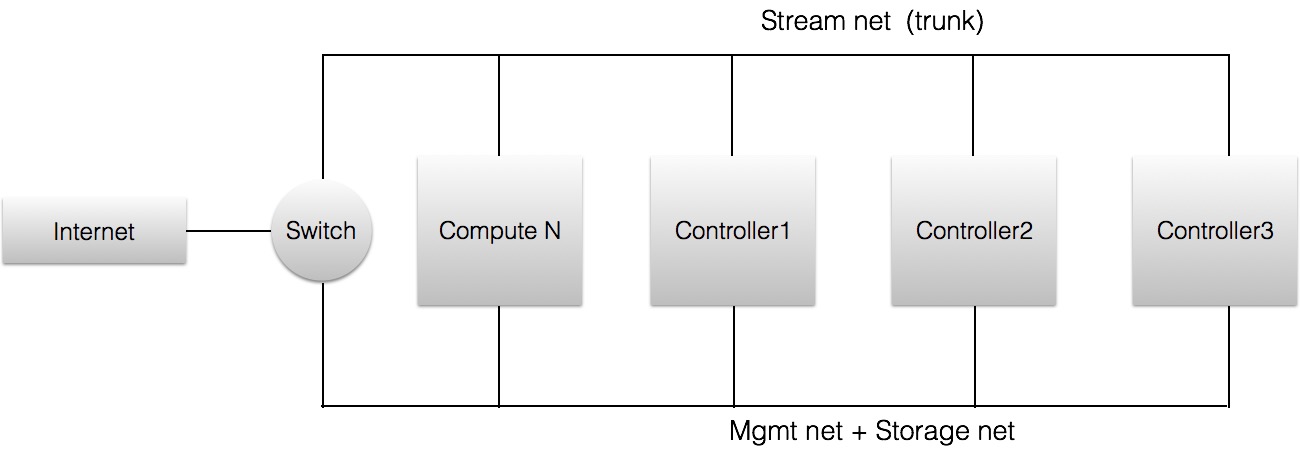
- 每个服务器两张网卡
- 每个服务器的硬盘除了sda之外都做ceph存储
推荐配置
- ceph 集群大概需要12块硬盘(小企业),最好是SSD
- 每个服务器需要8张网卡,两两做bund,提供管理网络,业务网络,外部网络,存储网络
- 计算节点需要超过128g内存
服务关系
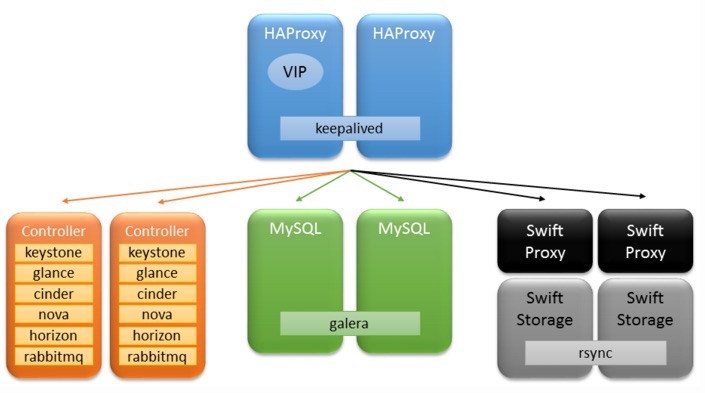
Controller
基础配置
1
2
3
4
5
6
7
8
| # 主机名ip映射关系
[root@controller1 rabbitmq(keystone_admin)]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.53.58 controller1
192.168.53.67 controller2
192.168.53.68 controller3
192.168.53.92 compute1
|
1
2
3
4
| yum update
yum install -y net-tools
yum install -y centos-release-openstack-liberty
yum install openstack-packstack
|
1
2
| vi /etc/profile
export LC_CTYPE=en_US.UTF-8
|
使用redhat的快速安装工具,CONFIG_COMPUTE_HOSTS只需要在一个controller上填写即可,不需要所有controller上都写上
1
| packstack --gen-answer-file a.txt
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| vim a.txt
CONFIG_DEFAULT_PASSWORD=bnc
CONFIG_MANILA_INSTALL=n
CONFIG_CEILOMETER_INSTALL=y
CONFIG_NAGIOS_INSTALL=n
CONFIG_SWIFT_INSTALL=n
CONFIG_PROVISION_DEMO=n
CONFIG_NEUTRON_ML2_TYPE_DRIVERS=vlan
CONFIG_NEUTRON_ML2_TENANT_NETWORK_TYPES=vlan
CONFIG_NEUTRON_ML2_VLAN_RANGES=default:13:2000 # 配置vlan 范围
CONFIG_NEUTRON_OVS_BRIDGE_MAPPINGS=default:br-data
CONFIG_NEUTRON_OVS_BRIDGE_IFACES=br-data:enp7s0f0
CONFIG_COMPUTE_HOSTS=192.168.53.92 # 计算节点都写在这里
|
1
| packstack --answer-file a.txt # 开始安装
|
安装完成
删除一个服务
1
2
3
4
5
6
7
8
| yum list | grep -i swift
openstack-service stop swift
openstack-service status swift
yum remove openstack-swift
rm -rf /etc/swift/
openstack service list
openstack service delete f18a5683261e496584a9d64d4d8f8ec1 #id号
|
修改
1
2
3
4
| vi /etc/cinder/cinder.conf
auth_uri = http://<你的ip>:5000 # 去掉/v2.0
openstack-service restart cinder
|
High Availability
-
RabbitMQ HA(不特别标注的话,每个节点都需要)
Rabbitmq 官方(www.rabbitmq.com)文档上搭建高可用集群的方式有两种:
对rabbitmq 官方cluster 文档的中文翻译http://m.oschina.net/blog/93548
尽管rabbitmq 本身支持cluster,但是cluster 并没有高可用。
一、 消息队列高可用(active/active)
二、 使用pacemaker+drbd(active/standby)
这里我们介绍的是第一种高可用方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| [root@controller1 ~(keystone_admin)]# ll /var/lib/rabbitmq/ -al # 查找.erlang.cookie
total 12
drwxr-x---. 3 rabbitmq rabbitmq 40 Jul 2 02:54 .
drwxr-xr-x. 46 root root 4096 Jul 2 04:45 ..
-r--------. 1 rabbitmq rabbitmq 20 Jul 2 00:00 .erlang.cookie
drwxr-xr-x. 4 rabbitmq rabbitmq 4096 Jul 2 02:54 mnesia
scp -rp /var/lib/rabbitmq/.erlang.cookie controller2:/var/lib/rabbitmq/
scp -rp /var/lib/rabbitmq/.erlang.cookie controller3:/var/lib/rabbitmq/
# 校验所有节点的 文件内容是否一致
md5sum /var/lib/rabbitmq/.erlang.cookie
#查看RabbitMQ状态
service rabbitmq-server status
#重启RabbitMQ
service rabbitmq-server restart
|
1
2
3
4
5
| #查看rabbitmq状态
rabbitmqctl cluster_status
Cluster status of node rabbit@rabbit1 ...
[{nodes,[{disc,[rabbit@rabbit1]}]},{running_nodes,[rabbit@rabbit1]}]
...done.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| rabbitmqctl stop_app
Stopping node rabbit@rabbit2 ...done.
rabbitmqctl join-cluster rabbit@controller1
Clustering node rabbit@rabbit2 with [rabbit@controller] ...done.
rabbitmqctl start_app
Starting node rabbit@rabbit2 ...done.
[root@controller2 ~(keystone_admin)]# rabbitmqctl cluster_status
Cluster status of node rabbit@controller2 ...
[{nodes,[{disc,[rabbit@controller1,rabbit@controller2,rabbit@controller3]}]},
{running_nodes,[rabbit@controller1,rabbit@controller3,rabbit@controller2]},
{cluster_name,<<"rabbit@controller1">>},
{partitions,[]},
{alarms,[{rabbit@controller1,[]},
{rabbit@controller3,[]},
{rabbit@controller2,[]}]}]
|
1
2
3
4
5
6
7
8
| #这条命令在任意节点上运行一次就可以
rabbitmqctl set_policy ha-all "^." '{"ha-mode":"all"}'
#这条命令在任意节点可以查看上一步的配置
[root@controller2 ~(keystone_admin)]# rabbitmqctl list_policies
Listing policies ...
/ ha-all all ^. {"ha-mode":"all"} 0
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 启动管理插件
[root@controller001 ~(keystone_admin)]# find / -name rabbitmq-plugins
# 启用插件
[root@controller2 ~(keystone_admin)]# /usr/sbin/rabbitmq-plugins enable rabbitmq_management
The following plugins have been enabled:
mochiweb
webmachine
rabbitmq_web_dispatch
amqp_client
rabbitmq_management_agent
rabbitmq_management
Applying plugin configuration to rabbit@controller2... started 6 plugins.
|
1
2
3
| 默认web ui url:http://server-name:15672
默认user/pass: guest/guest
|
rabbitmq界面
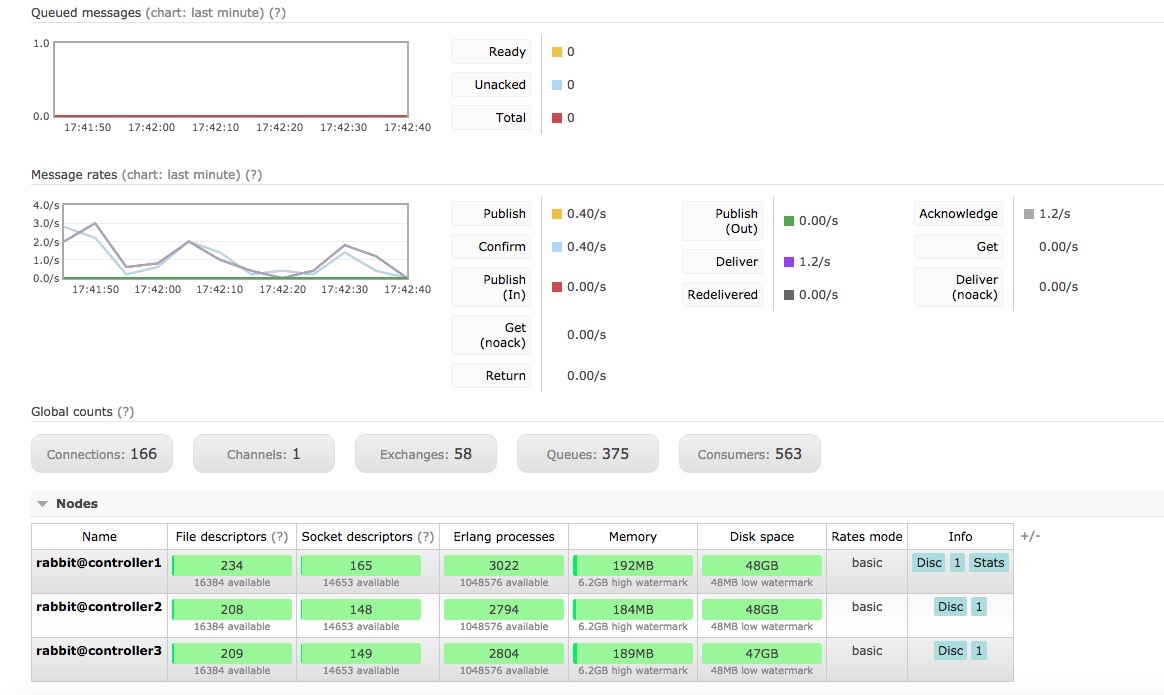
注意事项
-
为了防止数据丢失的发生,在任何情况下都应该保证至少有一个 node 是采用磁盘
node 方式。RabbitMQ 在很多情况下会阻止创建仅有内存 node 的 cluster ,但是如
果你通过手动将 cluster 中的全部磁盘 node 都停止掉或者强制 reset 所有的磁盘
node 的方式间接导致生成了仅有内存 node 的 cluster ,RabbitMQ 无法阻止你。你这
么做本身是很不明智的,因为会导致你的数据非常容易丢失。
-
当整个 cluster 不能工作了,最后一个失效的 node 必须是第一个重新开始工作的那
一个。如果这种情况得不到满足,所有 node 将会为最后一个磁盘 node 的恢复等待 30
秒。如果最后一个离线的 node 无法重新上线,我们可以通过命令 forget_cluster_node
将其从 cluster 中移除 - 具体参考 rabbitmqctl 的使用手册。
Mongodb 简介
MongoDB 是一个高性能,开源,无模式的文档型数据库,是当前NoSql 数据库中比较热门的一种。它在
许多场景下可用于替代传统的关系型数据库或键/值存储方式。Mongo 使用C++开发。Mongo 的官方网
站地址是:http://www.mongodb.org/,读者可以在此获得更详细的信息。
配置时候把controller1和controller2加入,controller3作为仲裁节点
1
2
3
| vi /etc/mongod.conf
replSet=s1 # 增加一个配置
service mongod restart
|
1
| yum install mongodb # 安装mongodb客户端
|
1
2
3
4
5
| [root@controller1 ~]# mongo --host controller1
MongoDB shell version: 2.6.11
connecting to: controller1:27017/test
> use admin
switched to db admin
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| > config = {_id:'s1', members:[{_id:0,host:'controller1:27017',priority:3},{_id:1,host:'controller2:27017'}]}
{
"_id" : "s1",
"members" : [
{
"_id" : 0,
"host" : "controller1:27017",
"priority" : 3
},
{
"_id" : 1,
"host" : "controller2:27017"
}
]
}
> rs.initiate(config)
{
"ok" : 0,
"errmsg" : "couldn't initiate : member controller2:27017 has data already, cannot initiate set. All members except initiator must be empty."
}
|
提示上述报错,说明需要删除从节点的数据
1
2
| [root@controller2 ~]# service mongod stop
Redirecting to /bin/systemctl stop mongod.service # 停mongod 服务,然后删除数据
|
1
2
3
4
5
6
7
8
| [root@controller2 ~]# ll /var/lib/mongodb/
total 65544
-rw-------. 1 mongodb mongodb 16777216 Jul 2 04:33 ceilometer.0
-rw-------. 1 mongodb mongodb 16777216 Jul 2 04:33 ceilometer.ns
drwxr-xr-x. 2 mongodb mongodb 6 Jul 2 21:39 journal
-rw-------. 1 mongodb mongodb 16777216 Jul 2 21:35 local.0
-rw-------. 1 mongodb mongodb 16777216 Jul 2 21:35 local.ns
-rwxr-xr-x. 1 mongodb mongodb 0 Jul 2 21:39 mongod.lock
|
1
2
3
4
5
6
| 默认数据目录在/var/lib/mongodb
rm /var/lib/mongodb/ -rf
[root@controller2 ~]# mkdir -p /var/lib/mongodb
[root@controller2 ~]# chown -R mongodb. /var/lib/mongodb
[root@controller2 ~]# service mongod restart
Redirecting to /bin/systemctl restart mongod.service
|
再尝试把controller2加入s1集群
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| [root@controller1 ~]# mongo --host controller1
MongoDB shell version: 2.6.11
connecting to: controller1:27017/test
>
> use admin
switched to db admin
> config = {_id:'s1',members:[{_id:0,host:'controller1:27017',priority:3},{_id:1,host:'controller2:27017'}]}
{
"_id" : "s1",
"members" : [
{
"_id" : 0,
"host" : "controller1:27017",
"priority" : 3
},
{
"_id" : 1,
"host" : "controller2:27017"
}
]
}
> rs.initiate(config)
{
"info" : "Config now saved locally. Should come online in about a minute.",
"ok" : 1
}
> rs.status()
{
"set" : "s1",
"date" : ISODate("2016-07-03T01:44:20Z"),
"myState" : 2,
"members" : [
{
"_id" : 0,
"name" : "controller1:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 1056,
"optime" : Timestamp(1467510253, 1),
"optimeDate" : ISODate("2016-07-03T01:44:13Z"),
"self" : true
},
{
"_id" : 1,
"name" : "controller2:27017",
"health" : 1,
"state" : 5,
"stateStr" : "STARTUP2",
"uptime" : 6,
"optime" : Timestamp(0, 0),
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2016-07-03T01:44:20Z"),
"lastHeartbeatRecv" : ISODate("2016-07-03T01:44:20Z"),
"pingMs" : 0,
"lastHeartbeatMessage" : "initial sync need a member to be primary or secondary to do our initial sync"
}
],
"ok" : 1
}
s1:SECONDARY>
|
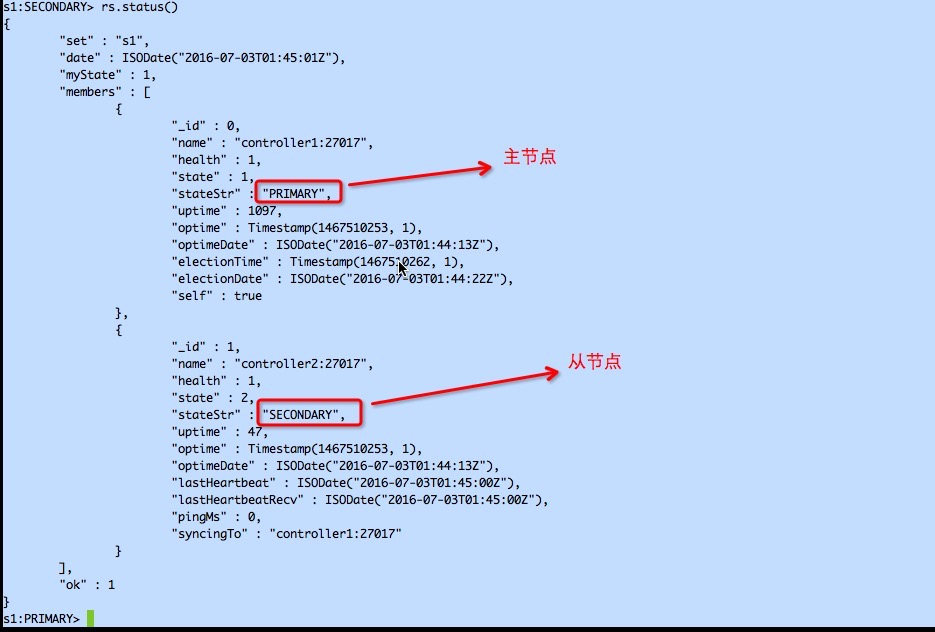
为了满足副本集内部选举算法的条件,还要添加一个仲裁节点
1
2
3
4
| [root@controller1 ~]# mongo --host controller1
> use admin
switched to db admin
rs.addArb(“controller3:27017”)
|
三个节点都ok了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| s1:PRIMARY> rs.status()
{
"set" : "s1",
"date" : ISODate("2016-07-03T01:49:06Z"),
"myState" : 1,
"members" : [
{
"_id" : 0,
"name" : "controller1:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 1342,
"optime" : Timestamp(1467510535, 1),
"optimeDate" : ISODate("2016-07-03T01:48:55Z"),
"electionTime" : Timestamp(1467510262, 1),
"electionDate" : ISODate("2016-07-03T01:44:22Z"),
"self" : true
},
{
"_id" : 1,
"name" : "controller2:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 292,
"optime" : Timestamp(1467510535, 1),
"optimeDate" : ISODate("2016-07-03T01:48:55Z"),
"lastHeartbeat" : ISODate("2016-07-03T01:49:06Z"),
"lastHeartbeatRecv" : ISODate("2016-07-03T01:49:04Z"),
"pingMs" : 0,
"syncingTo" : "controller1:27017"
},
{
"_id" : 2,
"name" : "controller3:27017",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 11,
"lastHeartbeat" : ISODate("2016-07-03T01:49:05Z"),
"lastHeartbeatRecv" : ISODate("2016-07-03T01:49:05Z"),
"pingMs" : 0
}
],
"ok" : 1
}
s1:PRIMARY>
|
Mariadb 简介
Galera 本质是一个wsrep 提供者(provider),运行依赖于wsrep 的API 接口。Wsrep API
定义了一系列应用回调和复制调用库,来实现事务数据库同步写集(writeset)复制以及相似应用。
目的在于从应用细节上实现抽象的,隔离的复制。虽然这个接口的主要目标是基于认证的多主复
制,但同样适用于异步和同步的主从复制。
安装rsync
1
2
| [root@controller1 ~]# yum install -y rsync
|
创建数据库的账号密码(只需要在controller1上配置,slave节点不需要)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| #创建同步数据库的账号密码
[root@controller1 ~]# mysql -uroot
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 1482
Server version: 5.5.40-MariaDB-wsrep MariaDB Server, wsrep_25.11.r4026
Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> GRANT ALL PRIVILEGES on *.* to bnc@'%' identified by 'bnc';
Query OK, 0 rows affected (0.00 sec)
#创建一个bnc用户, 密码也是bnc
MariaDB [(none)]> flush privileges
-> ;
Query OK, 0 rows affected (0.00 sec)
#刷新下权限
|
编辑文件(controller1和controller2上需要配置,controller3作为仲裁节点不需要配置)
1
2
3
4
5
6
7
8
9
10
11
12
| vim /etc/my.cnf.d/server.cnf
[mysqld]
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_name="my_wsrep_cluster"
wsrep_cluster_address="gcomm://" #空地址
#wsrep_cluster_address="gcomm://controller1,controller2,controller3"
wsrep_node_name=controller1
wsrep_node_address=controller1
wsrep_sst_method=rsync
wsrep_sst_auth=bnc:bnc
wsrep_slave_threads=8
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| [root@controller1 ~]# service mariadb stop
Redirecting to /bin/systemctl stop mariadb.service
[root@controller1 ~]# service mariadb start
Redirecting to /bin/systemctl start mariadb.service
[root@controller1 ~]# mysql -uroot
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 22
Server version: 5.5.40-MariaDB-wsrep MariaDB Server, wsrep_25.11.r4026
Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show status like 'wsrep%';
+------------------------------+--------------------------------------+
| Variable_name | Value |
+------------------------------+--------------------------------------+
| wsrep_local_state_uuid | b5b8da17-40c4-11e6-a3f9-1fe593f04af7 |
| wsrep_protocol_version | 5 |
| wsrep_last_committed | 4 |
| wsrep_replicated | 4 |
| wsrep_replicated_bytes | 1666 |
| wsrep_repl_keys | 18 |
| wsrep_repl_keys_bytes | 236 |
| wsrep_repl_data_bytes | 1174 |
| wsrep_repl_other_bytes | 0 |
| wsrep_received | 2 |
| wsrep_received_bytes | 146 |
| wsrep_local_commits | 4 |
| wsrep_local_cert_failures | 0 |
| wsrep_local_replays | 0 |
| wsrep_local_send_queue | 0 |
| wsrep_local_send_queue_avg | 0.000000 |
| wsrep_local_recv_queue | 0 |
| wsrep_local_recv_queue_avg | 0.500000 |
| wsrep_local_cached_downto | 1 |
| wsrep_flow_control_paused_ns | 0 |
| wsrep_flow_control_paused | 0.000000 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 0 |
| wsrep_cert_deps_distance | 1.000000 |
| wsrep_apply_oooe | 0.000000 |
| wsrep_apply_oool | 0.000000 |
| wsrep_apply_window | 1.000000 |
| wsrep_commit_oooe | 0.000000 |
| wsrep_commit_oool | 0.000000 |
| wsrep_commit_window | 1.000000 |
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| wsrep_cert_index_size | 14 |
| wsrep_causal_reads | 0 |
| wsrep_cert_interval | 0.000000 |
| wsrep_incoming_addresses | controller1:3306 |
| wsrep_cluster_conf_id | 1 |
| wsrep_cluster_size | 1 |
| wsrep_cluster_state_uuid | b5b8da17-40c4-11e6-a3f9-1fe593f04af7 |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_local_bf_aborts | 0 |
| wsrep_local_index | 0 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy <info@codership.com> |
| wsrep_provider_version | 3.5(rXXXX) |
| wsrep_ready | ON |
| wsrep_thread_count | 9 |
+------------------------------+--------------------------------------+
48 rows in set (0.01 sec)
|
在controller2上进行如下配置:
安装rsync
1
2
| [root@controller1 ~]# yum install -y rsync
|
1
2
3
4
5
6
7
8
9
| wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_name="my_wsrep_cluster"
#wsrep_cluster_address="gcomm://"
wsrep_cluster_address="gcomm://controller1,controller2,controller3"
wsrep_node_name=controller2
wsrep_node_address=controller2
wsrep_sst_method=rsync
wsrep_sst_auth=bnc:bnc
wsrep_slave_threads=8
|
重启mariadb报错
1
2
3
4
5
6
| [root@controller2 ~]# service mariadb start
Redirecting to /bin/systemctl start mariadb.service
Job for mariadb.service failed because the control process exited with error code. See "systemctl status mariadb.service" and "journalctl -xe" for details.
[root@controller2 ~]# openstack-service stop
[root@controller2 ~]# openstack-service status
|
有多少跟数据库有关的openstack服务全删除
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| [root@controller2 ~]# cd /var/lib/mysql/
[root@controller2 mysql]# ll
total 176200
-rw-rw----. 1 mysql mysql 16384 Jul 2 22:25 aria_log.00000001
-rw-rw----. 1 mysql mysql 52 Jul 2 22:25 aria_log_control
drwx------. 2 mysql mysql 4096 Jul 2 04:00 cinder
-rw-------. 1 mysql mysql 134219048 Jul 2 22:25 galera.cache
drwx------. 2 mysql mysql 4096 Jul 2 03:56 glance
-rw-rw----. 1 mysql mysql 104 Jul 2 22:25 grastate.dat
-rw-rw----. 1 mysql mysql 5242880 Jul 2 22:25 ib_logfile0
-rw-rw----. 1 mysql mysql 5242880 Jul 2 22:25 ib_logfile1
-rw-rw----. 1 mysql mysql 35651584 Jul 2 22:25 ibdata1
drwx------. 2 mysql mysql 4096 Jul 2 03:52 keystone
drwx------. 2 mysql root 4096 Jul 2 03:46 mysql
srwxrwxrwx. 1 mysql mysql 0 Jul 2 22:25 mysql.sock
drwx------. 2 mysql mysql 8192 Jul 2 04:08 neutron
drwx------. 2 mysql mysql 8192 Jul 2 04:03 nova
drwx------. 2 mysql mysql 4096 Jul 2 03:46 performance_schema
drwx------. 2 mysql root 6 Jul 2 03:46 test
[root@controller2 mysql]# rm -rf keystone/ cinder/ glance/ neutron/ nova/
|
看一下log
1
| /var/log/mariadb/mariadb.log
|
把controller2上的数据全删除,再从controller1上拷贝
1
2
3
4
| [root@controller1 ~]scp -pr /var/lib/mysql controller2:/var/lib/
[root@controller2 ~]chown -R mysql. /var/lib/mysql
[root@controller2 ~]service mariadb start
|
controller3的配置
1
2
3
4
5
| [root@controller3 ~]# service mariadb stop
Redirecting to /bin/systemctl stop mariadb.service
[root@controller3 ~]# systemctl disable mariadb
Removed symlink /etc/systemd/system/multi-user.target.wants/mariadb.service
|
1
2
3
4
5
| [root@controller3 ~]# egrep -v "^$|^#" /etc/sysconfig/garb
更改下面两行配置
GALERA_NODES="controller1:4567 controller2:4567 controller3:4567"
GALERA_GROUP="my_wsrep_cluster"
|
garbd是仲裁服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| [root@controller3 ~]# service garbd start
Redirecting to /bin/systemctl start garbd.service
[root@controller3 ~]# service garbd status
Redirecting to /bin/systemctl status garbd.service
● garbd.service - Galera Arbitrator Daemon
Loaded: loaded (/usr/lib/systemd/system/garbd.service; disabled; vendor preset: disabled)
Active: active (running) since Sat 2016-07-02 22:52:16 EDT; 3s ago
Docs: http://www.codership.com/wiki/doku.php?id=galera_arbitrator
Main PID: 6850 (garbd)
CGroup: /system.slice/garbd.service
└─6850 /usr/sbin/garbd -a gcomm://controller1:4567 -g my_wsrep_cluster
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.368 INFO: Shift...)
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.368 INFO: Sendi...7
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.369 INFO: Membe....
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.369 INFO: Shift...)
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.369 INFO: 0.0 (....
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.369 INFO: Shift...)
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.369 INFO: 1.0 (....
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.369 INFO: Membe....
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.369 INFO: Shift...)
Jul 02 22:52:17 controller3 garbd-wrapper[6850]: 2016-07-02 22:52:17.369 INFO: Membe....
Hint: Some lines were ellipsized, use -l to show in full.
|
可以看到集群的cluster size是3了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| [root@controller1 ~]# mysql -uroot
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 87
Server version: 5.5.40-MariaDB-wsrep MariaDB Server, wsrep_25.11.r4026
Copyright (c) 2000, 2015, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show status like 'wsrep%';
+------------------------------+--------------------------------------+
| Variable_name | Value |
+------------------------------+--------------------------------------+
| wsrep_local_state_uuid | b5b8da17-40c4-11e6-a3f9-1fe593f04af7 |
| wsrep_protocol_version | 5 |
| wsrep_last_committed | 1738 |
| wsrep_replicated | 1738 |
| wsrep_replicated_bytes | 980460 |
| wsrep_repl_keys | 7528 |
| wsrep_repl_keys_bytes | 100198 |
| wsrep_repl_data_bytes | 769030 |
| wsrep_repl_other_bytes | 0 |
| wsrep_received | 41 |
| wsrep_received_bytes | 2891 |
| wsrep_local_commits | 1738 |
| wsrep_local_cert_failures | 0 |
| wsrep_local_replays | 0 |
| wsrep_local_send_queue | 0 |
| wsrep_local_send_queue_avg | 0.009143 |
| wsrep_local_recv_queue | 0 |
| wsrep_local_recv_queue_avg | 0.048780 |
| wsrep_local_cached_downto | 1 |
| wsrep_flow_control_paused_ns | 0 |
| wsrep_flow_control_paused | 0.000000 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 0 |
| wsrep_cert_deps_distance | 1.002301 |
| wsrep_apply_oooe | 0.102417 |
| wsrep_apply_oool | 0.000000 |
| wsrep_apply_window | 1.108170 |
| wsrep_commit_oooe | 0.000000 |
| wsrep_commit_oool | 0.000000 |
| wsrep_commit_window | 1.005754 |
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| wsrep_cert_index_size | 36 |
| wsrep_causal_reads | 0 |
| wsrep_cert_interval | 0.110472 |
| wsrep_incoming_addresses | ,controller2:3306,controller1:3306 |
| wsrep_cluster_conf_id | 13 |
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | b5b8da17-40c4-11e6-a3f9-1fe593f04af7 |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_local_bf_aborts | 0 |
| wsrep_local_index | 2 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy <info@codership.com> |
| wsrep_provider_version | 3.5(rXXXX) |
| wsrep_ready | ON |
| wsrep_thread_count | 9 |
+------------------------------+--------------------------------------+
48 rows in set (0.00 sec)
|
最后一步
在controller1上改回这样的配置
1
2
| #wsrep_cluster_address="gcomm://"
wsrep_cluster_address="gcomm://controller1,controller2,controller3"
|
-
Keepalived(三个controller都安装)
检查keepalived是否安装
1
2
| [root@controller1 ~]# yum install keepalived
|
关闭selinux
1
2
3
4
5
6
7
| #永久生效
[root@controller1 ~]# vim /etc/selinux/config
SELINUX=disabled
#临时生效
[root@controller1 ~]# setenforce 0
[root@controller1 ~]# getenforce 0
Permissive
|
更改配置
为了防止虚拟IP乱飘,controller之间的priority可以设置为200,150,100
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| [root@controller1 ~]# vim /etc/keepalived/keepalived.conf
全部内容替换成如下
! Configuration File for keepalived
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance VI_1 {
interface enp7s0f1
virtual_router_id 53
state BACKUP
priority 200
# if use it,the openstack api do not response normally
# use_vmac virtualmac
#
advert_int 1
dont_track_primary
nopreempt
authentication {
auth_type PASS
auth_pass password
}
virtual_ipaddress {
192.168.53.23/32
}
track_script {
chk_haproxy
}
notify /usr/local/bin/keepalivednotify.sh
}
|
创建脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| vim /usr/local/bin/keepalivednotify.sh
#!/bin/bash
TYPE=$1
NAME=$2
STATE=$3
case $STATE in
"MASTER")
systemctl start haproxy
exit 0
;;
"BACKUP")
systemctl stop haproxy
exit 0
;;
"FAULT")
systemctl stop haproxy
exit 0
;;
*)
echo "Unknown state"
exit 1
;;
esac
[root@controller1 ~]# chmod +x /usr/local/bin/keepalivednotify.sh
|
自启动配置
1
2
3
| [root@controller1 ~]# service keepalived start
Redirecting to /bin/systemctl start keepalived.service
[root@controller1 ~]# chkconfig keepalived on
|
1
| [root@controller1 ~]# ip a # 查看vip是否生效
|
安装包
1
| [root@controller1 ~]# yum install haproxy
|
把keystone的数据库的IP地址全部换掉,换成haproxy的虚拟IP,可以使用navicat图形化界面
编辑文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| [root@controller1 ~(keystone_admin)]# vim /etc/haproxy/haproxy.cfg
[root@controller1 ~(keystone_admin)]# cat /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 10000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 10000
timeout connect 5000
timeout client 50000
timeout server 50000
listen stats
mode http
bind 0.0.0.0:8080
stats enable
stats refresh 30
stats hide-version
stats uri /haproxy_stats
stats realm Haproxy\ Status
stats auth admin:admin
stats admin if TRUE
|
在/etc/hosts中加入虚拟IP
1
2
3
4
5
| 192.168.53.58 controller1
192.168.53.67 controller2
192.168.53.68 controller3
192.168.53.23 controller
192.168.53.92 compute1
|
加入/etc/haproxy/haproxy.cfg末尾
1
2
3
4
5
| listen galera-cluster
bind controller:3305
balance source
server controller1 controller1:3306 check port 4567 inter 2000 rise 2 fall 5
server controller2 controller2:3306 check port 4567 inter 2000 rise 2 fall 5 backup
|
1
| service keepalived restart
|
可以看到haproxy在一台controller上是开启的
1
2
3
4
5
| listen mongodb-cluster
bind controller:27017
balance source
server controller1 controller1:27017 check inter 2000 rise 2 fall 5
server controller2 controller2:27017 check inter 2000 rise 2 fall 5 backup
|
1
| service keepalived restart
|
keystone
在/etc/keystone/keystone.conf中,将controller2,controller3上的密码改成与controller1一致的,端口号为haproxy的端口号
1
| connection = mysql+pymysql://keystone_admin:f15c18d2db7a4804@controller:3305/keystone
|
重启服务
1
2
3
| [root@controller2 ~]# systemctl stop openstack-keystone
#由httpd来接管keystone服务
[root@controller2 ~]# systemctl start httpd
|
更改keystonerc_admin文件,再source一下
1
2
3
4
5
6
7
8
9
10
| [root@controller1 ~(keystone_admin)]# cat keystonerc_admin
unset OS_SERVICE_TOKEN
export OS_USERNAME=admin
export OS_PASSWORD=79ab659cb04345b9
export OS_AUTH_URL=http://192.168.53.58:5000/v2.0
export PS1='[\u@\h \W(keystone_admin)]\$ '
export OS_TENANT_NAME=admin
export OS_REGION_NAME=RegionOne
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| [root@controller1 ~(keystone_admin)]# openstack service list
+----------------------------------+------------+-----------+
| ID | Name | Type |
+----------------------------------+------------+-----------+
| 13d5b7831a934442b8c16b2ac015c21c | nova_ec2 | ec2 |
| 2fafe24035ad4d06bced3cbc4f387c95 | keystone | identity |
| 3a2a2080cc4546ef9bc9ac9841323752 | neutron | network |
| 958afac483274321a953f1ad217d2576 | ceilometer | metering |
| 9ad0bd50a95c4fe1a9045aaa38353f66 | nova | compute |
| a3c70cc6b1a6410db36cbaba87afc05a | cinder | volume |
| b663d22cae2048598d23238184ea3794 | cinderv2 | volumev2 |
| c5bc60c03a384e889978b0b1b937347b | glance | image |
| d5c7e6b3545b414baffe9ce86e954bca | novav3 | computev3 |
+----------------------------------+------------+-----------+
[root@controller1 ~(keystone_admin)]#
[root@controller1 ~(keystone_admin)]#
[root@controller1 ~(keystone_admin)]#
[root@controller1 ~(keystone_admin)]#
[root@controller1 ~(keystone_admin)]#
[root@controller1 ~(keystone_admin)]# openstack project list
+----------------------------------+----------+
| ID | Name |
+----------------------------------+----------+
| 4b73b56644904c36ba9f3426ed20faaf | admin |
| cdd428776ab0435e87c82238981f9657 | services |
+----------------------------------+----------+
|
查看端口号是否被占用
1
| netstat -plunt | grep 5000
|
在vim /etc/haproxy/haproxy.cfg末尾加入下面配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| listen keystone-admin
bind controller:35358
balance source
option tcpka
option httpchk
option tcplog
server controller1 controller1:35357 check inter 10s
server controller2 controller2:35357 check inter 10s
server controller3 controller3:35357 check inter 10s
listen keystone-public
bind controller:5001
balance source
option tcpka
option httpchk
option tcplog
server controller1 controller1:5000 check inter 10s
server controller2 controller2:5000 check inter 10s
server controller3 controller3:5000 check inter 10s
|
更改keystonerc_admin文件,改为虚拟端口5001,再source一下
1
2
3
4
5
6
7
8
9
10
| [root@controller1 ~(keystone_admin)]# cat keystonerc_admin
unset OS_SERVICE_TOKEN
export OS_USERNAME=admin
export OS_PASSWORD=79ab659cb04345b9
export OS_AUTH_URL=http://192.168.53.58:5001/v2.0
export PS1='[\u@\h \W(keystone_admin)]\$ '
export OS_TENANT_NAME=admin
export OS_REGION_NAME=RegionOne
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| [root@controller2 ~(keystone_admin)]# openstack service list
+----------------------------------+------------+-----------+
| ID | Name | Type |
+----------------------------------+------------+-----------+
| 13d5b7831a934442b8c16b2ac015c21c | nova_ec2 | ec2 |
| 2fafe24035ad4d06bced3cbc4f387c95 | keystone | identity |
| 3a2a2080cc4546ef9bc9ac9841323752 | neutron | network |
| 958afac483274321a953f1ad217d2576 | ceilometer | metering |
| 9ad0bd50a95c4fe1a9045aaa38353f66 | nova | compute |
| a3c70cc6b1a6410db36cbaba87afc05a | cinder | volume |
| b663d22cae2048598d23238184ea3794 | cinderv2 | volumev2 |
| c5bc60c03a384e889978b0b1b937347b | glance | image |
| d5c7e6b3545b414baffe9ce86e954bca | novav3 | computev3 |
+----------------------------------+------------+-----------+
|
###注意点
当controller和haproxy在同一台机器上时,才有端口冲突问题,在上面改端口号的方法之外,还可以编辑下面文件,就可以解决端口冲突问题
1
2
3
4
5
6
| /etc/httpd/conf/ports.conf
Listen controller2:35357
Listen controller2:5000
Listen controller2:80
|
1
2
3
4
| [root@controller1 ~(keystone_admin)]# netstat -plunt | grep 35357
tcp 0 0 192.168.53.58:35357 0.0.0.0:* LISTEN 16951/httpd
[root@controller1 ~(keystone_admin)]# netstat -plunt | grep 5000
tcp 0 0 192.168.53.58:5000 0.0.0.0:* LISTEN 16951/httpd
|
glance
在vim /etc/haproxy/haproxy.cfg末尾加入下面配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| listen glance-registry
bind controller:9191
balance source
option tcpka
option tcplog
server controller1 controller1:9191 check inter 10s
server controller2 controller2:9191 check inter 10s
server controller3 controller3:9191 check inter 10s

listen glance-api
bind controller:9292
balance source
option tcpka
option httpchk
option tcplog
server controller1 controller1:9292 check inter 10s rise 2 fall 5
server controller2 controller2:9292 check inter 10s rise 2 fall 5
server controller3 controller3:9292 check inter 10s rise 2 fall 5
|
在每个controller的
/etc/glance/glance-api.conf进行更改
1
2
3
4
5
6
7
8
9
| #connection=mysql+pymysql://glance:96efbf0c50b84888@192.168.53.67/glance
connection=mysql+pymysql://glance:3d53cbf61a6b4c6c@controller:3305/glance
auth_uri=http://controller:5000/v2.0
identity_uri=http://controller:35357
admin_password=e5557a5325064c05 #这些需要跟controller1一致
bind_host=controller1
registry_host=controller1
rabbit_host=controller1,controller2,controller3
rabbit_hosts=controller1:5672,controller2:5672,controller3:5672
|
/etc/glance/glance-registry.conf进行更改
1
2
3
4
5
6
| connection=mysql+pymysql://glance:3d53cbf61a6b4c6c@controller:3305/glance
bind_host=controller1
auth_uri=http://controller:5000/v2.0
identity_uri=http://controller:35357
admin_password=e5557a5325064c05
|
重启glance服务
1
| openstack-service restart glance
|
1
2
3
4
| [root@controller1 ~(keystone_admin)]# netstat -plunt | grep 9191
tcp 0 0 192.168.53.58:9191 0.0.0.0:* LISTEN 29665/python2
[root@controller1 ~(keystone_admin)]# netstat -plunt | grep 9292
tcp 0 0 192.168.53.58:9292 0.0.0.0:* LISTEN 29669/python2
|
重启keepalived服务
1
| service keepalived restart
|
先启动程序在后台,可用于检查配置是否有问题
1
| [root@controller1 ~(keystone_admin)]# haproxy -f /etc/haproxy/haproxy.cfg
|
检查glance服务是否OK
1
2
3
4
5
| [root@controller2 ~(keystone_admin)]# glance image-list
+----+------+
| ID | Name |
+----+------+
+----+------+
|
nova
在vim /etc/haproxy/haproxy.cfg末尾加入下面配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| listen nova-compute-api
bind controller:8774
balance source
option tcpka
option httpchk
option tcplog
server controller1 controller1:8774 check inter 10s
server controller2 controller2:8774 check inter 10s
server controller3 controller3:8774 check inter 10s
listen nova-metadata
bind controller:8775
balance source
option tcpka
option tcplog
server controller1 controller1:8775 check inter 10s
server controller2 controller2:8775 check inter 10s
server controller3 controller3:8775 check inter 10s
|
vim /etc/nova/nova.conf
改为下面配置,做适当修改,可用wscp拷贝,再进行相应修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
| [root@controller1 ~(keystone_admin)]# egrep -v "^$|^#" /etc/nova/nova.conf
[DEFAULT]
novncproxy_host=controller1
novncproxy_port=6080
use_ipv6=False
notify_api_faults=False
state_path=/var/lib/nova
report_interval=10
enabled_apis=ec2,osapi_compute,metadata
ec2_listen=controller1
ec2_listen_port=8773
ec2_workers=24
osapi_compute_listen=controller1
osapi_compute_listen_port=8774
osapi_compute_workers=24
metadata_listen=controller1
metadata_listen_port=8775
metadata_workers=24
service_down_time=60
rootwrap_config=/etc/nova/rootwrap.conf
volume_api_class=nova.volume.cinder.API
api_paste_config=api-paste.ini
auth_strategy=keystone
use_forwarded_for=False
fping_path=/usr/sbin/fping
cpu_allocation_ratio=16.0
ram_allocation_ratio=1.5
network_api_class=nova.network.neutronv2.api.API
default_floating_pool=public
force_snat_range =0.0.0.0/0
metadata_host=192.168.53.67
dhcp_domain=novalocal
security_group_api=neutron
scheduler_default_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,CoreFilter
scheduler_driver=nova.scheduler.filter_scheduler.FilterScheduler
vif_plugging_is_fatal=True
vif_plugging_timeout=300
firewall_driver=nova.virt.firewall.NoopFirewallDriver
debug=False
verbose=True
log_dir=/var/log/nova
use_syslog=False
syslog_log_facility=LOG_USER
use_stderr=True
notification_driver =nova.openstack.common.notifier.rabbit_notifier,ceilometer.compute.nova_notifier
notification_topics=notifications
rpc_backend=rabbit
sql_connection=mysql+pymysql://nova:55d6235461c34c4e@controller:3305/nova
image_service=nova.image.glance.GlanceImageService
lock_path=/var/lib/nova/tmp
osapi_volume_listen=0.0.0.0
novncproxy_base_url=http://192.168.53.23:6080/vnc_auto.html
[api_database]
[barbican]
[cells]
[cinder]
catalog_info=volumev2:cinderv2:publicURL
[conductor]
use_local=False
[cors]
[cors.subdomain]
[database]
[ephemeral_storage_encryption]
[glance]
api_servers=controller:9292
[guestfs]
[hyperv]
[image_file_url]
[ironic]
[keymgr]
[keystone_authtoken]
auth_uri=http://controller:5000/v2.0
identity_uri=http://controller:35357
admin_user=nova
admin_password=0f2d84e61de642a2
admin_tenant_name=services
[libvirt]
vif_driver=nova.virt.libvirt.vif.LibvirtGenericVIFDriver
[matchmaker_redis]
[matchmaker_ring]
[metrics]
[neutron]
service_metadata_proxy=True
metadata_proxy_shared_secret =9b8066d60bf948f7
url=http://controller:9696
admin_username=neutron
admin_password=e8b3a57702d3447b
admin_tenant_name=services
region_name=RegionOne
admin_auth_url=http://controller:5000/v2.0
auth_strategy=keystone
ovs_bridge=br-int
extension_sync_interval=600
timeout=30
default_tenant_id=default
[osapi_v21]
[oslo_concurrency]
[oslo_messaging_amqp]
[oslo_messaging_qpid]
[oslo_messaging_rabbit]
amqp_durable_queues=False
kombu_reconnect_delay=1.0
rabbit_host=controller1,controller2,controller3
rabbit_port=5672
rabbit_hosts=controller1:5672,controller2:5672,controller3:5672
rabbit_use_ssl=False
rabbit_userid=guest
rabbit_password=guest
rabbit_virtual_host=/
rabbit_ha_queues=False
heartbeat_timeout_threshold=0
heartbeat_rate=2
[oslo_middleware]
[rdp]
[serial_console]
[spice]
[ssl]
[trusted_computing]
[upgrade_levels]
[vmware]
[vnc]
[workarounds]
[xenserver]
[zookeeper]
[osapi_v3]
enabled=False
|
1
2
3
4
5
6
| #停止nova服务
openstack-service stop nova
#启动nova服务
openstack-service start nova
#查看状态
openstack-service status nova
|
1
2
3
4
5
6
| [root@controller1 ~(keystone_admin)]# netstat -plunt | grep 8774
tcp 0 0 192.168.53.58:8774 0.0.0.0:* LISTEN 16661/python2
[root@controller1 ~(keystone_admin)]# netstat -plunt | grep 8775
tcp 0 0 192.168.53.58:8775 0.0.0.0:* LISTEN 16661/python2
[root@controller1 ~(keystone_admin)]# netstat -plunt | grep 6080
tcp 0 0 192.168.53.58:6080 0.0.0.0:* LISTEN 13794/python2
|
在再每个节点上重启keepalived
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| [root@controller2 ~(keystone_admin)]# nova service-list
+----+------------------+-------------+----------+---------+-------+----------------------------+-----------------+
| Id | Binary | Host | Zone | Status | State | Updated_at | Disabled Reason |
+----+------------------+-------------+----------+---------+-------+----------------------------+-----------------+
| 1 | nova-consoleauth | controller1 | internal | enabled | up | 2016-07-03T06:54:05.000000 | - |
| 2 | nova-scheduler | controller1 | internal | enabled | up | 2016-07-03T06:54:05.000000 | - |
| 3 | nova-conductor | controller1 | internal | enabled | up | 2016-07-03T06:54:05.000000 | - |
| 4 | nova-cert | controller1 | internal | enabled | up | 2016-07-03T06:54:05.000000 | - |
| 5 | nova-compute | compute1 | nova | enabled | up | 2016-07-03T06:54:13.000000 | - |
| 6 | nova-conductor | controller2 | internal | enabled | up | 2016-07-03T06:54:15.000000 | - |
| 9 | nova-consoleauth | controller2 | internal | enabled | up | 2016-07-03T06:54:15.000000 | - |
| 18 | nova-cert | controller2 | internal | enabled | up | 2016-07-03T06:54:15.000000 | - |
| 21 | nova-scheduler | controller2 | internal | enabled | up | 2016-07-03T06:54:15.000000 | - |
| 24 | nova-consoleauth | controller3 | internal | enabled | up | 2016-07-03T06:54:17.000000 | - |
| 27 | nova-cert | controller3 | internal | enabled | up | 2016-07-03T06:54:17.000000 | - |
| 30 | nova-conductor | controller3 | internal | enabled | up | 2016-07-03T06:54:17.000000 | - |
| 42 | nova-scheduler | controller3 | internal | enabled | up | 2016-07-03T06:54:17.000000 | - |
+----+------------------+-------------+----------+---------+-------+----------------------------+-----------------+
|
neutron
在vim /etc/haproxy/haproxy.cfg末尾加入下面配置
1
2
3
4
5
6
| listen vnc
bind controller:6080
balance source
server controller1 controller1:6080 check inter 10s
server controller2 controller2:6080 check inter 10s
server controller3 controller3:6080 check inter 10s
|
1
2
3
4
5
6
7
8
9
| listen neutron-server
bind controller:9696
balance source
option tcpka
option httpchk
option tcplog
server controller1 controller1:9696 check inter 10s
server controller2 controller2:9696 check inter 10s
server controller3 controller3:9696 check inter 10s
|
在/etc/neutron/neutron.conf中修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| [DEFAULT]
verbose = True
router_distributed = False
debug = False
state_path = /var/lib/neutron
use_syslog = False
use_stderr = True
log_dir =/var/log/neutron
bind_host = controller1
bind_port = 9696
core_plugin =neutron.plugins.ml2.plugin.Ml2Plugin
service_plugins =router
auth_strategy = keystone
base_mac = fa:16:3e:00:00:00
mac_generation_retries = 16
dhcp_lease_duration = 86400
dhcp_agent_notification = True
allow_bulk = True
allow_pagination = False
allow_sorting = False
allow_overlapping_ips = True
advertise_mtu = False
agent_down_time = 75
router_scheduler_driver = neutron.scheduler.l3_agent_scheduler.ChanceScheduler
allow_automatic_l3agent_failover = False
dhcp_agents_per_network = 1
l3_ha = False
api_workers = 24
rpc_workers = 24
use_ssl = False
notify_nova_on_port_status_changes = True
notify_nova_on_port_data_changes = True
nova_url = http://controller:8774/v2
nova_region_name =RegionOne
nova_admin_username =nova
nova_admin_tenant_name =services
nova_admin_password =0f2d84e61de642a2
nova_admin_auth_url =http://controller:5000/v2.0
send_events_interval = 2
rpc_response_timeout=60
rpc_backend=rabbit
control_exchange=neutron
lock_path=/var/lib/neutron/lock
[matchmaker_redis]
[matchmaker_ring]
[quotas]
[agent]
root_helper = sudo neutron-rootwrap /etc/neutron/rootwrap.conf
report_interval = 30
[keystone_authtoken]
auth_uri = http://controller:5000/v2.0
identity_uri = http://controller:35357
admin_tenant_name = services
admin_user = neutron
admin_password = e8b3a57702d3447b
[database]
connection = mysql+pymysql://neutron:e2620946daed4a13@controller:3305/neutron
max_retries = 10
retry_interval = 10
min_pool_size = 1
max_pool_size = 10
idle_timeout = 3600
max_overflow = 20
[nova]
[oslo_concurrency]
[oslo_policy]
[oslo_messaging_amqp]
[oslo_messaging_qpid]
[oslo_messaging_rabbit]
kombu_reconnect_delay = 1.0
rabbit_host = controller1,controller2,controller3
rabbit_port = 5672
rabbit_hosts = controller1:5672,controller2:5672,controller3:5672
rabbit_use_ssl = False
rabbit_userid = guest
rabbit_password = guest
rabbit_virtual_host = /
rabbit_ha_queues = False
heartbeat_rate=2
heartbeat_timeout_threshold=0
[qos]
notification_drivers = message_queue
|
重启neutron服务
1
| openstack-service restart neutron
|
查看 neutron agent-list
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| [root@controller2 ~(keystone_admin)]# neutron agent-list
+--------------------------------------+--------------------+-------------+-------+----------------+---------------------------+
| id | agent_type | host | alive | admin_state_up | binary |
+--------------------------------------+--------------------+-------------+-------+----------------+---------------------------+
| 07222119-8557-4bfa-ac91-a487fcaa5af0 | DHCP agent | controller2 | :-) | True | neutron-dhcp-agent |
| 14316fc6-be8d-428c-a5c3-5dc29a71c0f2 | Metadata agent | controller3 | :-) | True | neutron-metadata-agent |
| 19484a6f-97a8-4bd1-9c46-26981aa99058 | DHCP agent | controller1 | :-) | True | neutron-dhcp-agent |
| 31afaa71-9b88-4d70-b055-3ad5e2f571e3 | Open vSwitch agent | controller3 | :-) | True | neutron-openvswitch-agent |
| 352c4254-03f8-41a3-97d9-49ccd58a35ba | Open vSwitch agent | compute1 | :-) | True | neutron-openvswitch-agent |
| 3684ae49-0090-426e-aaa9-6ea7532d1f02 | Open vSwitch agent | controller1 | :-) | True | neutron-openvswitch-agent |
| 6169e996-5640-4313-8814-0845e1f9726a | Metadata agent | controller2 | :-) | True | neutron-metadata-agent |
| 77d56e37-549e-4ec8-8805-c99f8820a955 | L3 agent | controller2 | :-) | True | neutron-l3-agent |
| 998292f4-9a88-404c-8688-04eedb612ea4 | Open vSwitch agent | controller2 | :-) | True | neutron-openvswitch-agent |
| a0ceb7d5-ee2d-49c1-920f-ae717913c2f6 | L3 agent | controller1 | :-) | True | neutron-l3-agent |
| a4f09402-9d1d-4660-842c-01bf3da06e25 | Metadata agent | controller1 | :-) | True | neutron-metadata-agent |
| c67bb302-6911-49a6-8e84-b251eb5ac2e4 | DHCP agent | controller3 | :-) | True | neutron-dhcp-agent |
| fa79912d-0bf6-4373-b6a8-c1b8746f3931 | L3 agent | controller3 | :-) | True | neutron-l3-agent |
+--------------------------------------+--------------------+-------------+-------+----------------+---------------------------+
|
cinder
配置cinder
编辑文件 /etc/cinder/cinder.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| [root@controller1 ~(keystone_admin)]# egrep -v "^$|^#" /etc/cinder/cinder.conf
[DEFAULT]
glance_host = controller
enable_v1_api = True
enable_v2_api = True
host = controller1
storage_availability_zone = nova
default_availability_zone = nova
auth_strategy = keystone
enabled_backends = lvm
osapi_volume_listen = controller1
osapi_volume_workers = 24
nova_catalog_info = compute:nova:publicURL
nova_catalog_admin_info = compute:nova:adminURL
debug = False
verbose = True
log_dir = /var/log/cinder
notification_driver =messagingv2
rpc_backend = rabbit
control_exchange = openstack
api_paste_config=/etc/cinder/api-paste.ini
[BRCD_FABRIC_EXAMPLE]
[CISCO_FABRIC_EXAMPLE]
[cors]
[cors.subdomain]
[database]
connection = mysql+pymysql://cinder:73e7560f8da542b3@controller:3305/cinder
[fc-zone-manager]
[keymgr]
[keystone_authtoken]
auth_uri = http://controller:5000
identity_uri = http://controller:35357
admin_user = cinder
admin_password = a1db95ea939449b5
admin_tenant_name = services
[matchmaker_redis]
[matchmaker_ring]
[oslo_concurrency]
[oslo_messaging_amqp]
[oslo_messaging_qpid]
[oslo_messaging_rabbit]
amqp_durable_queues = False
kombu_ssl_keyfile =
kombu_ssl_certfile =
kombu_ssl_ca_certs =
rabbit_host = controller1,controller2,controller3
rabbit_port = 5672
rabbit_hosts = controller1:5672,controller2:5672,controller3:5672
rabbit_use_ssl = False
rabbit_userid = guest
rabbit_password = guest
rabbit_virtual_host = /
rabbit_ha_queues = False
heartbeat_timeout_threshold = 0
heartbeat_rate = 2
[oslo_middleware]
[oslo_policy]
[oslo_reports]
[profiler]
[lvm]
iscsi_helper=lioadm
volume_group=cinder-volumes
iscsi_ip_address=192.168.53.58
volume_driver=cinder.volume.drivers.lvm.LVMVolumeDriver
volumes_dir=/var/lib/cinder/volumes
iscsi_protocol=iscsi
volume_backend_name=lvm
|
在vim /etc/haproxy/haproxy.cfg末尾加入下面配置
1
2
3
4
5
6
7
8
9
| listen cinder-api
bind controller:8776
balance source
option tcpka
option httpchk
option tcplog
server controller1 controller1:8776 check inter 10s rise 2 fall 5
server controller2 controller2:8776 check inter 10s rise 2 fall 5
server controller3 controller3:8776 check inter 10s rise 2 fall 5
|
重启服务
1
2
| openstack-service restart cinder
|
验证服务
1
2
3
4
5
| [root@controller2 ~(keystone_admin)]# cinder list
+----+--------+------------------+------+------+-------------+----------+-------------+-------------+
| ID | Status | Migration Status | Name | Size | Volume Type | Bootable | Multiattach | Attached to |
+----+--------+------------------+------+------+-------------+----------+-------------+-------------+
+----+--------+------------------+------+------+-------------+----------+-------------+-------------+
|
ceilometer
更改ceilometer配置
vi /etc/ceilometer/ceilometer.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
| [DEFAULT]
http_timeout = 600
debug = False
verbose = True
log_dir = /var/log/ceilometer
use_syslog = False
syslog_log_facility = LOG_USER
use_stderr = True
notification_topics = notifications
rpc_backend = rabbit
meter_dispatcher=database
event_dispatcher=database
[alarm]
evaluation_interval = 60
record_history = True
evaluation_service=ceilometer.alarm.service.SingletonAlarmService
partition_rpc_topic=alarm_partition_coordination
[api]
port = 8777
host = controller2
[central]
[collector]
udp_address = 0.0.0.0
udp_port = 4952
[compute]
[coordination]
[database]
metering_time_to_live = -1
event_time_to_live = -1
alarm_history_time_to_live = -1
connection = mongodb://controller:27017/ceilometer
idle_timeout = 3600
min_pool_size = 1
max_pool_size = 10
max_retries = 10
retry_interval = 10
max_overflow = 20
[dispatcher_file]
[dispatcher_gnocchi]
[event]
[exchange_control]
[hardware]
[ipmi]
[keystone_authtoken]
auth_uri = http://controller:5000/v2.0
identity_uri = http://controller:35357
admin_user = ceilometer
admin_password = bnc
admin_tenant_name = services
[matchmaker_redis]
[matchmaker_ring]
[meter]
[notification]
ack_on_event_error = True
store_events = False
[oslo_concurrency]
[oslo_messaging_amqp]
[oslo_messaging_qpid]
[oslo_messaging_rabbit]
rabbit_host = controller1,controller2,controller3
rabbit_port = 5672
rabbit_hosts = controller1:5672,controller2:5672,controller3:5672
rabbit_use_ssl = False
rabbit_userid = guest
rabbit_password = guest
rabbit_virtual_host = /
rabbit_ha_queues = False
heartbeat_timeout_threshold = 0
heartbeat_rate = 2
[oslo_policy]
[polling]
[publisher]
metering_secret=0301fa12b3f349c9
[publisher_notifier]
[publisher_rpc]
[rgw_admin_credentials]
[service_credentials]
os_username = ceilometer
os_password = bnc
os_tenant_name = services
os_auth_url = http://controller:5000/v2.0
os_region_name = RegionOne
[service_types]
[vmware]
[xenapi]
|
重启ceilometer服务
1
2
| openstack-service restart ceilometer
|
1
2
3
4
5
| [root@controller2 ~(keystone_admin)]# ceilometer meter-list
+------+------+------+-------------+---------+------------+
| Name | Type | Unit | Resource ID | User ID | Project ID |
+------+------+------+-------------+---------+------------+
+------+------+------+-------------+---------+------------+
|
在vim /etc/haproxy/haproxy.cfg末尾加入下面配置
1
2
3
4
5
6
| listen ceilometer_api
bind controller:8777
balance source
server controller1 controller1:8777 check inter 2000 rise 2 fall 5
server controller2 controller2:8777 check inter 2000 rise 2 fall 5
server controller3 controller3:8777 check inter 2000 rise 2 fall 5
|
- 注意点:每次添加完/etc/haproxy/haproxy.cfg配置后都需要在各个controller上重启keepalived或者在active的haproxy节点上重启haproxy服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| [api]
#
# From ceilometer
#
# The port for the ceilometer API server. (integer value)
# Minimum value: 1
# Maximum value: 65535
# Deprecated group/name - [DEFAULT]/metering_api_port
#port = 8777
port = 8777
# The listen IP for the ceilometer API server. (string value)
#host = 0.0.0.0
host = controller2
|
dashboard
在vim /etc/haproxy/haproxy.cfg末尾加入下面配置
1
2
3
4
5
6
7
8
| listen dashboard
bind controller:80
balance source
option httpchk
option tcplog
server controller1 controller1:80 check inter 10s
server controller2 controller2:80 check inter 10s
server controller3 controller3:80 check inter 10s
|
HAproxy提供的界面
1
| http://192.168.53.58:8080/haproxy_stats
|
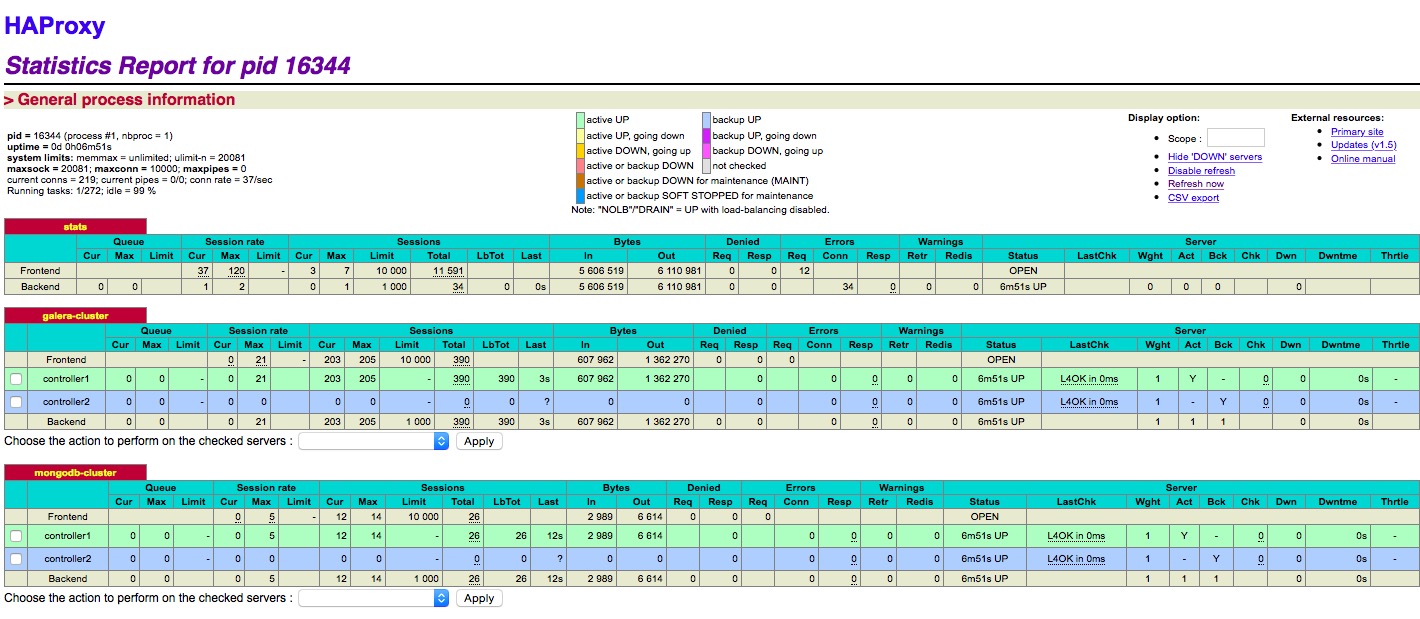
httpd 配置(每个节点都需要)
1
2
3
4
5
6
| mv /etc/httpd/conf.d/15-default.conf /etc/httpd/conf.d/15-default.conf.back
vim /etc/openstack-dashboard/local_settings
SECRET_KEY = '95b37c567cc4431e9ae875f3eb228c48' # 保持三个controller的SECRET_KEY一致
service httpd restart
|
vip的dashboard
1
| http://192.168.53.24/dashboard
|